Epsilla
Premium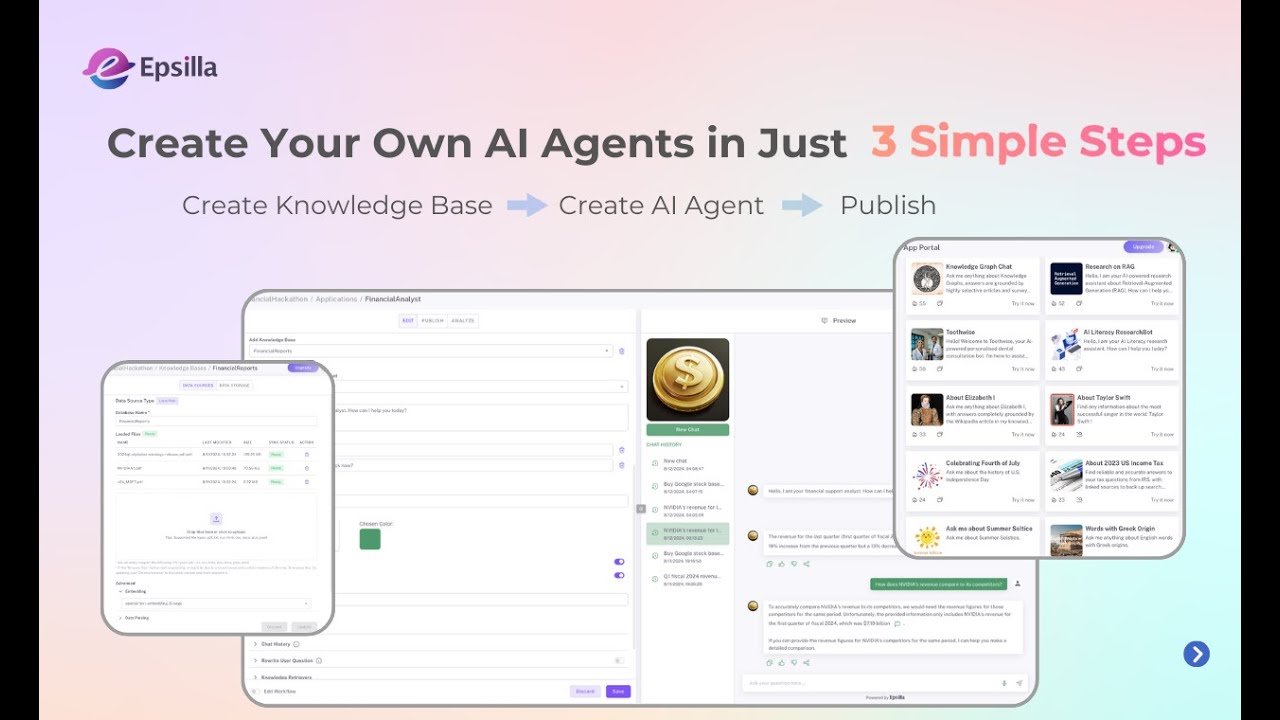
Epsilla: A Deep Dive into the High-Performance Vector Database for AI Applications
In the rapidly evolving landscape of Artificial Intelligence, the ability to efficiently store, manage, and query high-dimensional data is absolutely paramount. This is precisely where cutting-edge vector databases like Epsilla (found at epsilla.com) come into play. As AI models become exponentially more sophisticated and data volumes explode, tools that can power real-time semantic search, intelligent recommendation engines, and advanced Retrieval-Augmented Generation (RAG) systems are not just beneficial, but indispensable. This comprehensive SEO review delves deep into Epsilla, meticulously examining its core features, highlighting its significant advantages, acknowledging potential drawbacks, and critically comparing how it stacks up against other prominent players in the competitive AI ecosystem.
What is Epsilla?
Epsilla is a high-performance, scalable vector database meticulously designed to accelerate AI applications by enabling lightning-fast and remarkably accurate similarity search over vast collections of vector embeddings. Built with an unwavering focus on unparalleled performance, low latency, and exceptional ease of use, Epsilla empowers developers and organizations to build truly intelligent applications that understand context and meaning, transcending the limitations of mere keyword matching.
1. Deep Features Analysis: Unpacking Epsilla's Robust Capabilities
Epsilla distinguishes itself through a robust and thoughtfully engineered set of features tailored specifically for modern, data-intensive AI workloads. Here's a detailed exploration:
1.1 Core Vector Database Functionality
- High-Performance Vector Search: At its very core, Epsilla excels at Approximate Nearest Neighbor (ANN) search, a critical technique that allows for ultra-fast retrieval of semantically similar vectors from colossal datasets. This capability is absolutely crucial for applications demanding real-time responses and deep contextual understanding.
- Scalability and Distributed Architecture: Engineered for enterprise-grade workloads, Epsilla inherently supports horizontal scaling. This means it can seamlessly handle ever-growing data volumes and increasing query loads by intelligently distributing data and processing tasks across multiple nodes. This ensures consistent, high-level performance even as your AI application's demands skyrocket.
- Low Latency Operations: For use cases where speed is non-negotiable, such as real-time recommendation systems, fraud detection, or interactive AI chatbots, latency is a critical factor. Epsilla is meticulously engineered for minimal query response times, guaranteeing a smooth, responsive, and seamless user experience.
- Hybrid Search (Vector + Scalar Filtering): Going far beyond pure vector similarity, Epsilla empowers users to combine advanced vector search with traditional scalar filtering. This means you can filter results based on specific metadata fields (e.g., category, date, price range, user ID) in conjunction with semantic similarity. This unique capability enables incredibly precise, highly contextual, and therefore, profoundly relevant search results.
- Data Persistence: Epsilla ensures the durability and integrity of your invaluable vector embeddings, safeguarding them against data loss and providing reliable storage for your AI models.
1.2 Developer Experience and Integration
- Intuitive Python SDK: Epsilla offers a highly user-friendly and well-documented Python SDK, making it remarkably straightforward for data scientists, machine learning engineers, and developers to integrate sophisticated vector database capabilities into their Python-based AI workflows and applications.
- SQL-like Interface: For developers accustomed to the familiarity and power of relational databases, Epsilla thoughtfully provides a SQL-like query interface. This significantly reduces the learning curve, making data manipulation, querying, and schema definition much more intuitive and accessible.
- Comprehensive RESTful API: A robust and well-defined RESTful API ensures maximum flexibility, allowing for seamless integration with virtually any programming language, framework, or existing application environment. This makes Epsilla highly adaptable to diverse architectural needs.
- Cloud-Native Deployment: With native support for containerization technologies like Docker and orchestration platforms like Kubernetes, Epsilla is purpose-built for modern cloud infrastructures. This enables effortless deployment, efficient orchestration, and streamlined management in both public and private cloud environments.
1.3 Robustness, Flexibility & Openness
- Schema Definition: Users have the ability to define explicit schemas for their collections, providing essential structure and ensuring consistency, integrity, and predictable behavior for their vector data.
- Open-Source Core & Enterprise Ready: Epsilla proudly offers an open-source core, fostering transparency, community contributions, and broader adoption. Simultaneously, it provides enterprise-grade features and support, making it suitable for mission-critical deployments with stringent requirements.
- Wide Range of Versatile Use Cases: Epsilla is a highly versatile tool, capable of powering a diverse spectrum of cutting-edge AI applications, including but not limited to:
- Retrieval-Augmented Generation (RAG): Significantly enhancing the factual accuracy and currency of large language models (LLMs) by providing them with up-to-date and domain-specific knowledge from external sources.
- Semantic Search: Revolutionizing search by moving beyond simplistic keyword matching to truly understanding the meaning, intent, and context behind user queries.
- Recommendation Systems: Delivering highly personalized and relevant product, content, or service suggestions based on complex user preferences, historical behavior, and item characteristics.
- Anomaly Detection: Proactively identifying unusual patterns, outliers, or deviations in data by comparing new data points to existing clusters or learned norms.
2. Pros and Cons of Epsilla
2.1 Pros (Key Advantages)
- Exceptional Performance: Engineered for raw speed, Epsilla delivers consistently low-latency vector search, which is absolutely critical for real-time and interactive AI applications.
- High Scalability & Reliability: Its meticulously designed distributed architecture allows it to effortlessly scale with your ever-expanding data and user base, guaranteeing future-proof operations and robust performance.
- Superior Hybrid Search Capabilities: The powerful ability to combine precise vector search with intelligent scalar filtering provides incredibly relevant and highly accurate results, offering a significant competitive advantage.
- Developer-Friendly Ecosystem: With an intuitive Python SDK, familiar SQL-like interface, and comprehensive REST API, developers can rapidly integrate and efficiently manage Epsilla within their existing workflows.
- True Cloud-Native Design: Robust Kubernetes and Docker support dramatically simplify deployment, orchestration, and long-term management in any modern cloud or hybrid environment.
- Highly Versatile: Applicable across a broad spectrum of AI tasks, from foundational RAG to advanced recommendations, making it an incredibly valuable and general-purpose tool in the AI stack.
- Open-Source & Enterprise Ready: Offers the dual benefits of open-source transparency, flexibility, and community engagement, alongside the stability, features, and support required for demanding enterprise deployments.
2.2 Cons (Potential Disadvantages)
- Learning Curve for New Paradigms: While Epsilla itself is developer-friendly, the underlying concepts of vector databases—such as embeddings, similarity metrics, and Approximate Nearest Neighbor (ANN) algorithms—can present a learning curve for those entirely new to the field of semantic search and modern AI data infrastructure.
- Infrastructure Overhead (Self-Hosted): Deploying, configuring, and managing a distributed vector database, particularly in a self-hosted environment, can require significant operational expertise, dedicated DevOps resources, and ongoing maintenance effort.
- Ecosystem Maturity (Relative to Traditional DBs): As a relatively newer category of databases, the broader ecosystem (including advanced tooling, third-party integrations, and widespread community knowledge) might still be maturing compared to decades-old relational or NoSQL database technologies.
- Cost for Enterprise Features/Managed Service: While an open-source core provides a baseline, advanced enterprise features, premium support, or fully managed cloud services will naturally come with associated costs that need to be factored into budgeting.
- External Embedding Generation: Epsilla expertly stores and queries vector embeddings, but the crucial step of generating these embeddings (using various models like OpenAI, Hugging Face, Cohere, etc.) remains an external process that users must manage and integrate into their pipelines separately.
3. Comparison and Alternatives: Epsilla in the Vector Database Landscape
The vector database market is incredibly vibrant, dynamic, and competitive, with several strong contenders vying for developer attention. Epsilla stands out for its exceptional performance and powerful hybrid search capabilities, but it's essential to understand its unique position relative to other popular and well-regarded tools.
3.1 Epsilla vs. Pinecone
- Pinecone: Often considered a trailblazer in the managed vector database space, Pinecone is renowned for its fully managed, incredibly high-performance cloud service. It emphasizes extreme ease of use and a strong focus on delivering an excellent developer experience. Pinecone offers unparalleled scalability and reliability by abstracting away all infrastructure management from the user.
- Epsilla vs. Pinecone Comparison:
- Deployment Model: Pinecone operates exclusively as a managed cloud service, completely abstracting infrastructure. Epsilla offers significantly more flexibility with robust self-hosting options (Docker, Kubernetes) alongside potential managed service offerings. This flexibility provides Epsilla an edge for organizations requiring strict data sovereignty, compliance, or private cloud deployments.
- Control & Openness: Epsilla's open-source component offers greater transparency, customizability, and community-driven development potential compared to Pinecone's entirely proprietary, closed-source platform.
- Hybrid Search: Both platforms offer robust and sophisticated hybrid search capabilities, which are crucial for achieving refined and highly relevant search results.
- Pricing Structure: Pinecone's pricing is typically based on usage (number of vectors stored, queries executed). Epsilla's self-hosted version might offer lower operational costs for very large-scale deployments, assuming an organization possesses the internal DevOps expertise to manage it effectively.
3.2 Epsilla vs. Milvus
- Milvus: A prominent open-source vector database celebrated for its high performance, scalability, and comprehensive feature set. It is specifically designed for massive-scale vector search scenarios and offers extensive configurability. Zilliz, the company behind Milvus, also provides a fully managed cloud service for Milvus.
- Epsilla vs. Milvus Comparison:
- Open-Source Focus: Both Epsilla and Milvus boast a strong open-source presence. Milvus, having been in the market longer, generally benefits from a larger, more established community and a more extensive history of contributions.
- Architecture & Complexity: Milvus features a highly distributed, cloud-native architecture that, while powerful, can be perceived as more complex to set up, operate, and manage, particularly for smaller teams or those new to distributed systems. Epsilla also emphasizes scalability but aims to provide a relatively simpler deployment path, especially with its Docker images and focused design.
- Query Interface: Both platforms offer comprehensive SDKs and APIs for integration. Epsilla's distinctive SQL-like interface might be particularly appealing to developers transitioning from traditional relational databases, offering a familiar interaction model.
- Maturity & Features: Milvus, due to its longer market presence, might have more battle-tested integrations, a broader range of advanced features (e.g., streaming vector data processing in some versions), and a more mature ecosystem. Epsilla is rapidly advancing, focusing on core performance and its unique hybrid search advantages.
3.3 Epsilla vs. Weaviate
- Weaviate: An open-source vector database that uniquely positions itself as a vector search engine and a knowledge graph. A significant differentiator for Weaviate is its ability to integrate directly with various machine learning models (e.g., for embedding generation, classification) within or alongside the database itself, often reducing the need for completely external services for model inference. It supports a modular architecture for data ingestion and processing.
- Epsilla vs. Weaviate Comparison:
- Integrated ML & MLOps: Weaviate's core strength lies in its modular architecture that allows embedding models (from providers like OpenAI, Cohere, Hugging Face) to be run directly within or closely coupled with the database. This significantly simplifies the MLOps pipeline for embedding generation. In contrast, Epsilla focuses on being a highly efficient vector database, requiring embedding models to be managed and called externally.
- Knowledge Graph Capabilities: Weaviate's graph-like capabilities and focus on linking data points enable more complex semantic relationships, which can be highly beneficial for specific, interconnected semantic search and knowledge graph applications. Epsilla maintains a sharper focus purely on high-performance vector storage and querying.
- Ease of Use & Abstraction: Both tools prioritize developer-friendliness. Weaviate's integrated ML might reduce boilerplate code but can also introduce additional complexity in its configuration and understanding of its modular system. Epsilla maintains a clear separation of concerns (storage/query vs. embedding generation), which can sometimes lead to a more straightforward setup for its core function.
- Performance Philosophy: Both are engineered for high performance. The choice between them often hinges on whether the integrated ML and knowledge graph features of Weaviate provide a critical advantage for a specific use case, versus Epsilla's dedicated, streamlined, and highly optimized vector database approach.
Conclusion: Epsilla's Formidable Position in the AI Data Stack
Epsilla emerges as a truly formidable player in the burgeoning vector database arena, offering a compelling and well-balanced blend of high performance, enterprise-grade scalability, and exceptionally developer-centric features. Its strong emphasis on sophisticated hybrid search capabilities and native cloud deployment makes it an excellent, future-proof choice for businesses aspiring to build and deploy highly sophisticated, real-time AI applications, especially those that demand fine-grained control over their underlying infrastructure, adhere to strict data sovereignty requirements, or prioritize an open-source yet robust solution.
While the inherent learning curve associated with vector databases is a general consideration for the entire category, Epsilla's unwavering commitment to providing intuitive interfaces, comprehensive documentation, and an approachable SQL-like syntax helps significantly mitigate this challenge. For organizations prioritizing raw speed, unparalleled scalability, the flexibility afforded by an open-source core, and robust enterprise-grade capabilities, Epsilla undoubtedly presents a powerful, reliable, and intelligently designed solution for navigating and mastering the increasingly complex world of high-dimensional vector embeddings.